Introduction
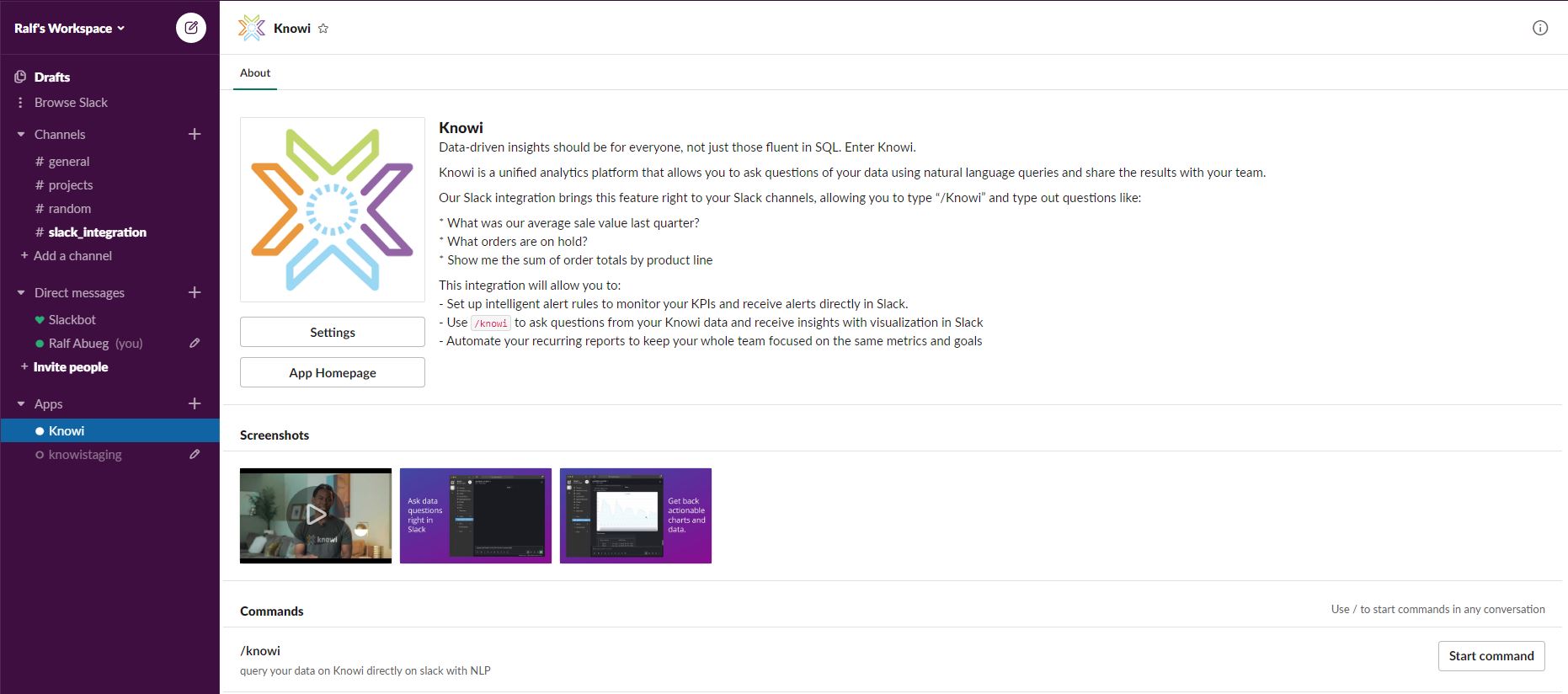
Knowi’s slack integration combines our powerful search-based analytics capabilities with Slack’s intuitive messaging user interface. This enables users to ask questions of their data, receive answers, and visualize those answers within Slack.
There are two steps to enable search-based analytics in Slack:
- Install the Knowi bot, which requires admin privileges in Slack
- Connect your Knowi account within Slack.
Sections
- Installing the Knowi Bot
- Natural Language Processing Settings
- Data Management for Natural Language Processing
Installing the Knowi Bot
To get started, add the Knowi bot to your Slack workspace:
- Click on this link:

- Click “Allow” in order to grant Knowi permission to access your Slack workspace
- Enter the login credentials for your Knowi account and click “Sign In”
- Click “Allow” in order to grant the Slack Knowi app with permission to access Knowi
- Click “Get Started” and “open in Slack”. This will redirect you to the Knowi app in your workspace
- In the “Commands” section at the bottom of the page, click “Start command”
- You should now see the image below, and can begin entering questions preceded by the command /knowi
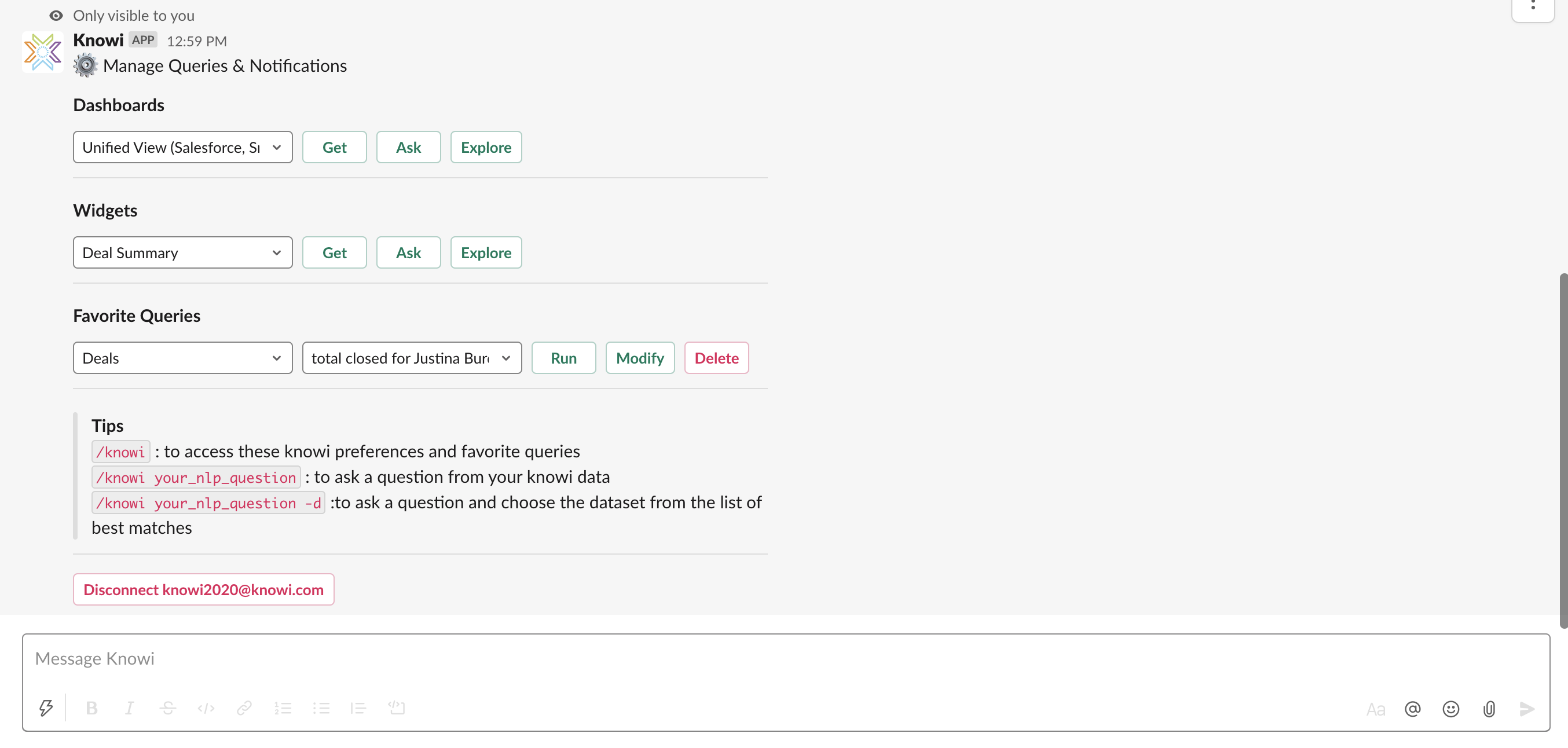
For documentation on using Knowi’s Slack integration as a User, click here.
Natural Language Processing Settings
Knowi’s Search-based Analytics can be configured by navigating to User Settings > Natural Language Processing Setting
You can toggle the settings below to disable/enable. By default, they are enabled.
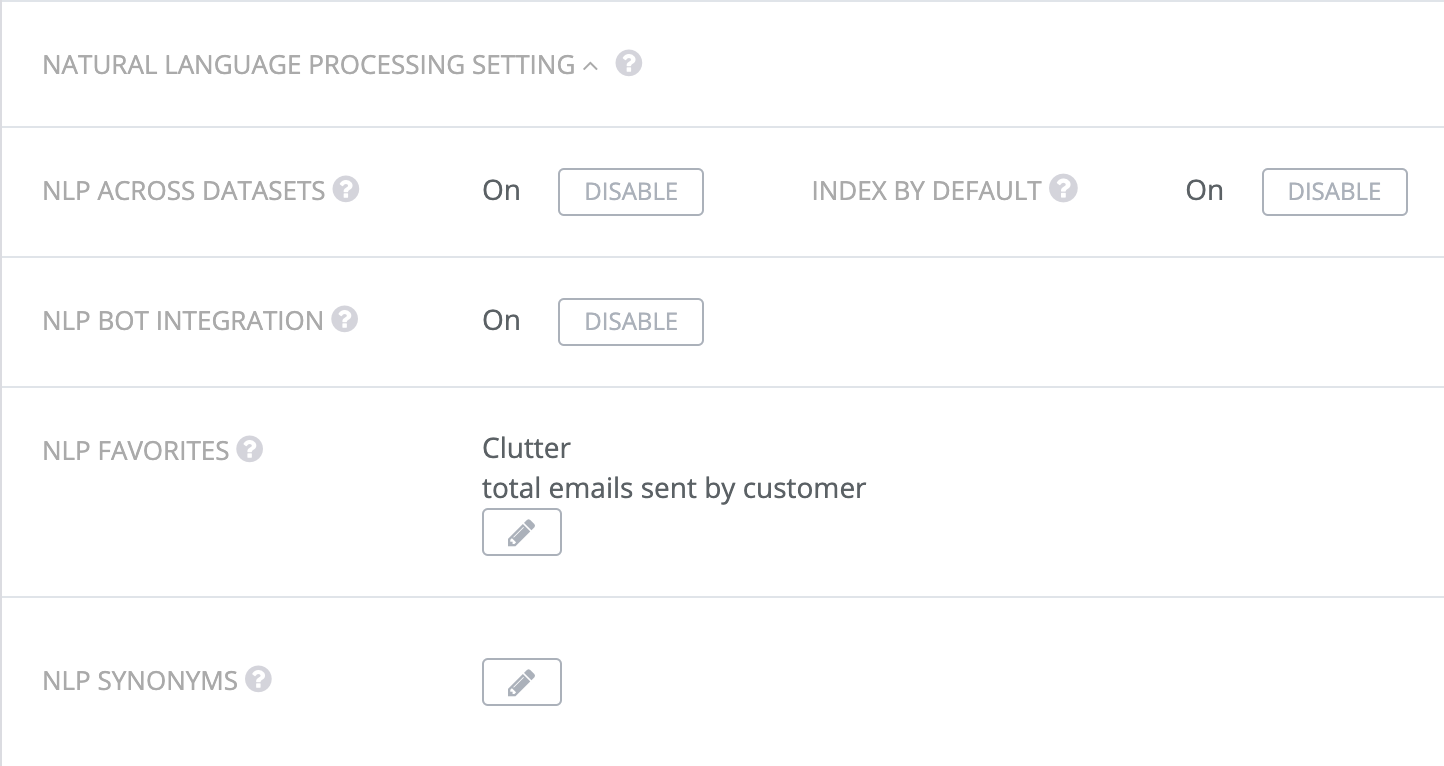
NLP Across Datasets
When Enabled/ON: enables natural language interface across datasets and the NLP search bar appears above dashboards.
When Disabled/OFF: the NLP text bar will disappear from the top of the dashboards. Note, that you will still be able to use the NLP within individual widgets in the Analyze screen.
Index By Default
By default, all datasets will be automatically indexed. Turning this off will automatically exclude NEW datasets from being indexed. Datasets can be individually indexed from the Data Management section of the query listing Queries > Data Management > NLP . If you would like to turn off historical datasets for indexing as a one time operation, use the option in the pop up.
NLP Slack Integration
When Enabled/ON, enables natural language interface from Slack.
NLP Favorites
List of the categories that you saved to Favorite in Slack. You can modify existing categories or add new ones here.
Data Management for Natural Language Processing
To configure NLP settings at the dataset level, navigate to Queries > Data Management > NLP. It can also be accessed at the widget level via More Settings > Data Diagram > Edit Dataset (click on the pencil icon in the blue box representing the dataset).
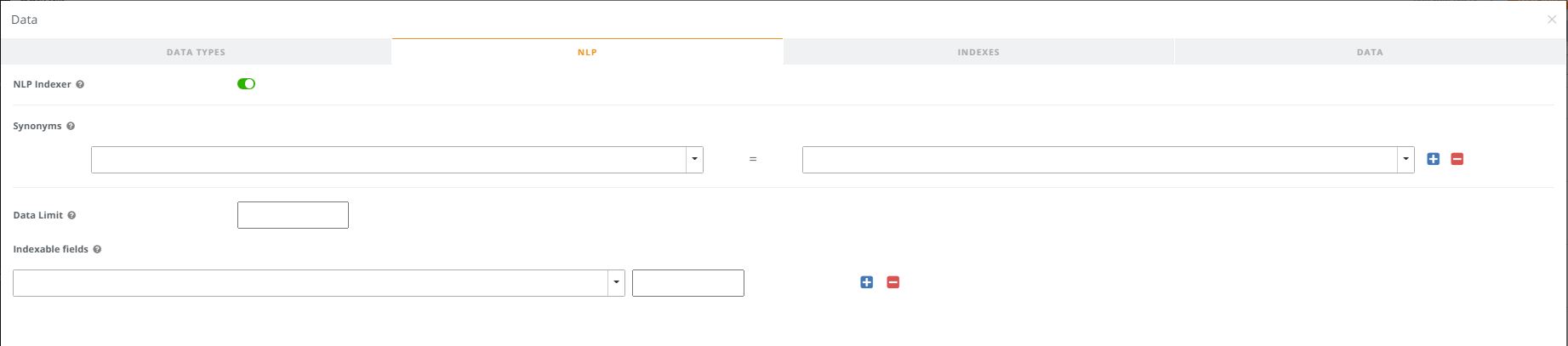
NLP Indexer
Defaults to ON. Turning it off will exclude the dataset from Search-based Analytics/NLP queries. Note that it may take a few minutes for the change to take effect.
Synonyms
Useful for adding context awareness to your Search-based Analytics/NLP queries. For example, if you have a field in your dataset named “customer”, you can add a synonym "tag" to this field such as "shopper", "buyer", "client", etc. So, when you type in a question like "total sent by client", it will recognize the term "client" as equivalent to the field "customer". Multiple synonyms can be added for each field.
Data Limit
Option to limit the amount of records to process for NLP. Defaults to 200k records when empty. Set to 0 for unlimited.
Indexable Fields
Gives you control on the ability to set unique values on String fields that are often used as part of a condition. For example, consider the query statement “Total sales for Motorcycles in Alameda” on a dataset that pans millions of records. Motorcycles may be a value in the Product fields and Alameda in the County field. Having these fields defined here, along with setting unique values limit will speed up the NLP processing.
Index values from another Dataset
By default, values are sampled from the original dataset (if the query is non-direct). Pointing to another dataset gives you fine grained control over the values that can be driven from another dataset. The values are determined for the first column of a dataset. If the dataset has multiple columns, values will be determined for the column name matching the field to index.