The Naive Bayes Classifier technique is based on the so-called Bayesian theorem and is particularly suited when the dimensionality of the inputs is high. Despite its simplicity, Naive Bayes can often outperform more sophisticated classification methods.
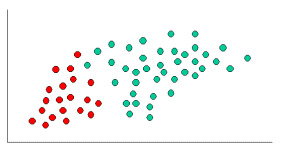
To demonstrate the concept of Naïve Bayes Classification, consider the example displayed in the illustration above. As indicated, the objects can be classified as either GREEN or RED. Our task is to classify new cases as they arrive, i.e., decide to which class label they belong, based on the currently existing objects.
Since there are twice as many GREEN objects as RED, it is reasonable to believe that a new case (which hasn't been observed yet) is twice as likely to have membership GREEN rather than RED. In the Bayesian analysis, this belief is known as the prior probability. Prior probabilities are based on previous experience, in this case, the percentage of GREEN and RED objects, and often used to predict outcomes before they actually happen.
The users can change the following settings:
| Generation Model | Multinomial or Bernoulli. The multinomial model generates one term in each position of the document. The multivariate Bernoulli model or Bernoulli model generates an indicator for each term, either indicating the presence of the term in the document or indicating absence.
|
| Add k-smoothing | By default, we use add-one or Laplace smoothing, which simply adds one to each count to eliminate zeros. |