Once your data is loaded and your predictor attribute selected, the next step is to ensure that your data is ready for the machine learning algorithms to successfully run against.
Knowi will lead you through a series of data preparation steps (some are mandatory and some are optional) prior to running the algorithms of your choice.
Note that the results of each step are saved. If a user leaves the data preparation area and returns later the system will direct them to the next step in the process automatically. The user also always has access to view their data by clicking in the top right hand corner of the box.
Data Types
Firstly, we need to ensure that all data types are correct. The user has the option to modify the data types, if necessary. The user simply selects the correct data type per column and then selects 'Next Step'
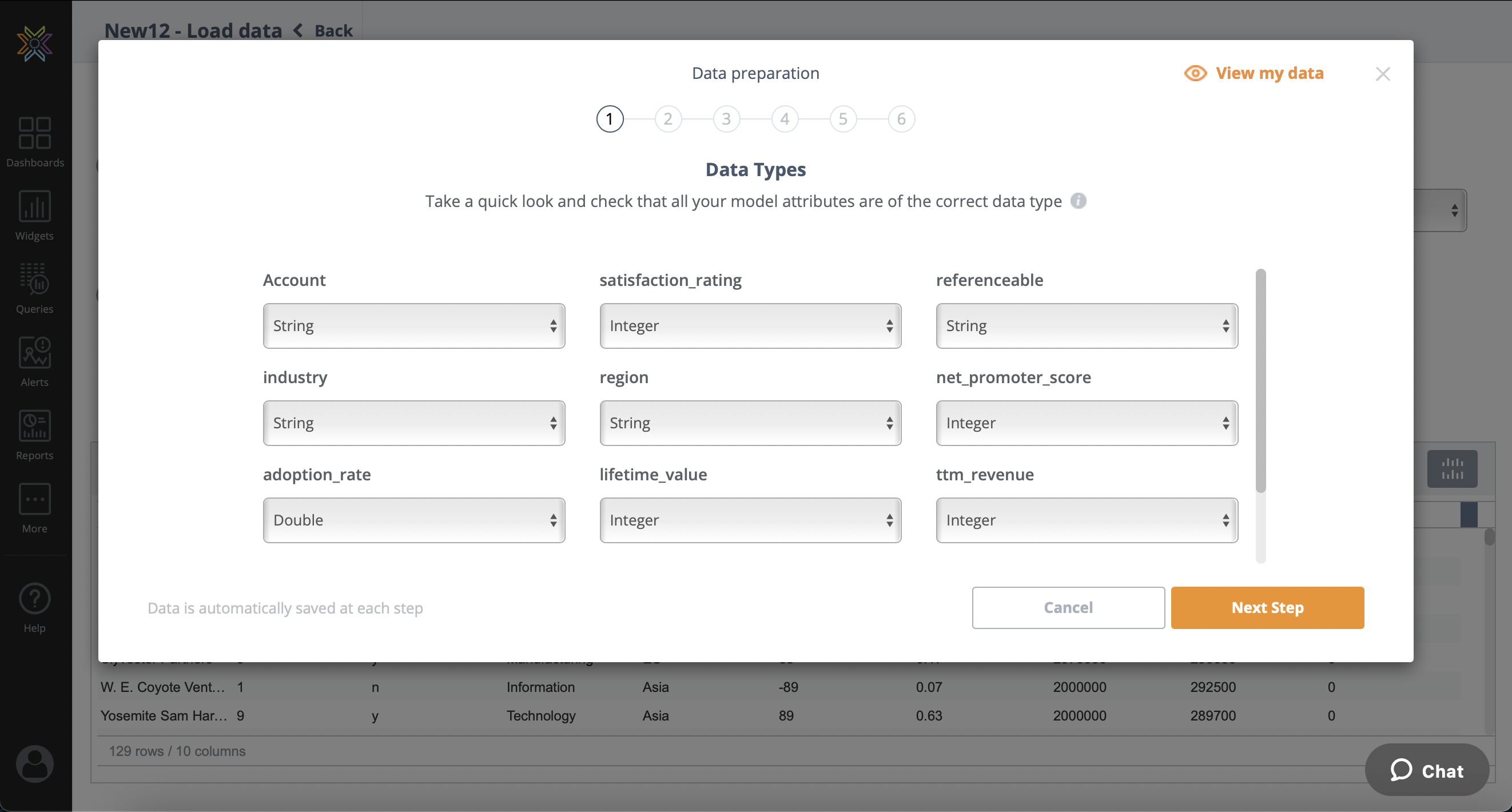
Outliers
The next step is the identification of potential outliers in your data. Knowi will highlight these values and allow the user to either remove all of them, remove selected values or skip the step completely.
Note that the user also always has the ability to go back to the Cloud9QL processing area and inspect their data again.
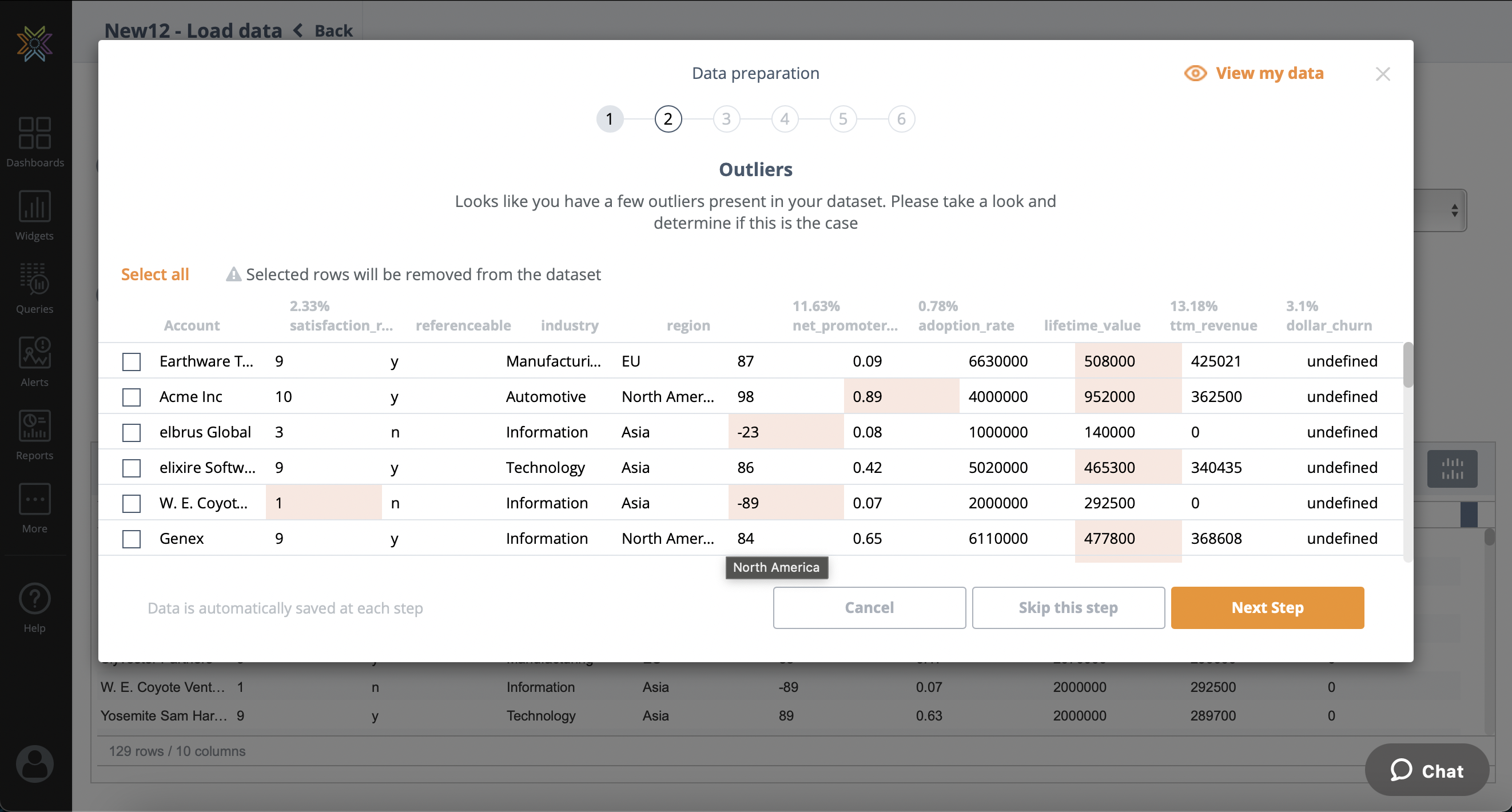
Missing Values
It is important that the training dataset does not have any missing values (null values). Rows containing missing values will either need to be removed or imputed (calculated) using the mean of the associated column. The user has the option to remove or impute values. This step is mandatory.
The system will allow the user to:
- enter a % above which all rows with this percentage of missing values will be removed from the dataset (eg, remove all rows where there are >25% missing numerical values)
- enter a % above which all columns with this percentage of missing numerical values will be removed from the dataset (eg, remove all columns where there are >9% missing values)
- impute the remaining missing values on a column by column basis
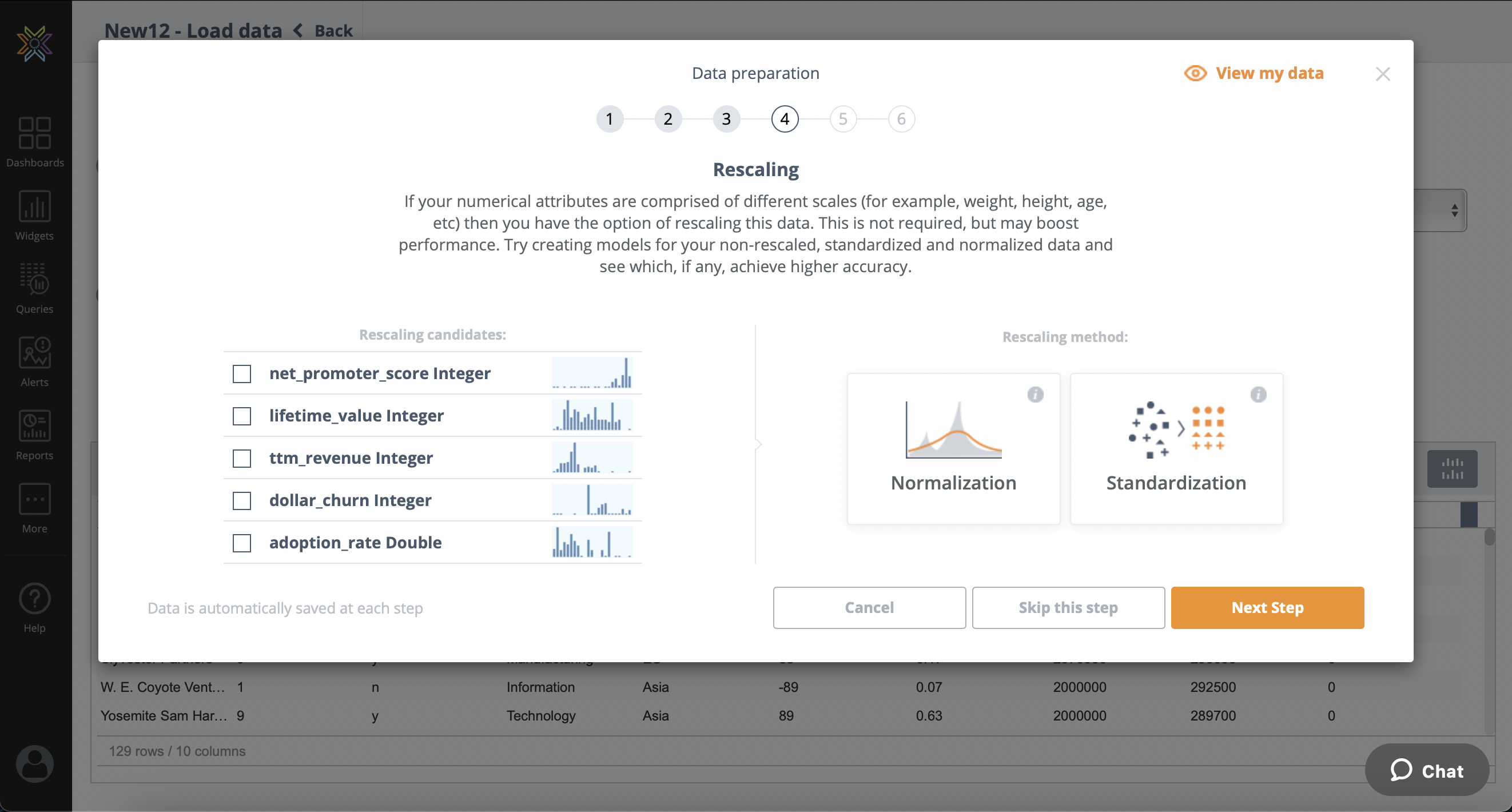
Rescaling
If your numerical attributes are comprised of different scales (for example, weight, height, age,
etc.) then you have the option of rescaling this data. This is not required, but may boost
performance. Try creating different models for your non-rescaled, standardized and normalized data and see which ones achieve higher accuracy.
Two methods of rescaling are offered; Normalization (when you do not know the distribution of your data or the distribution is not Gaussian; this will set all values across the board to be between 0 and 1) and Standardization (if your data is Gaussian; this will transform the data to have a mean of 0 and a standard deviation of 1).
Simply select the data items to rescale, the method and chose 'Next Step'.
This step may be skipped entirely.
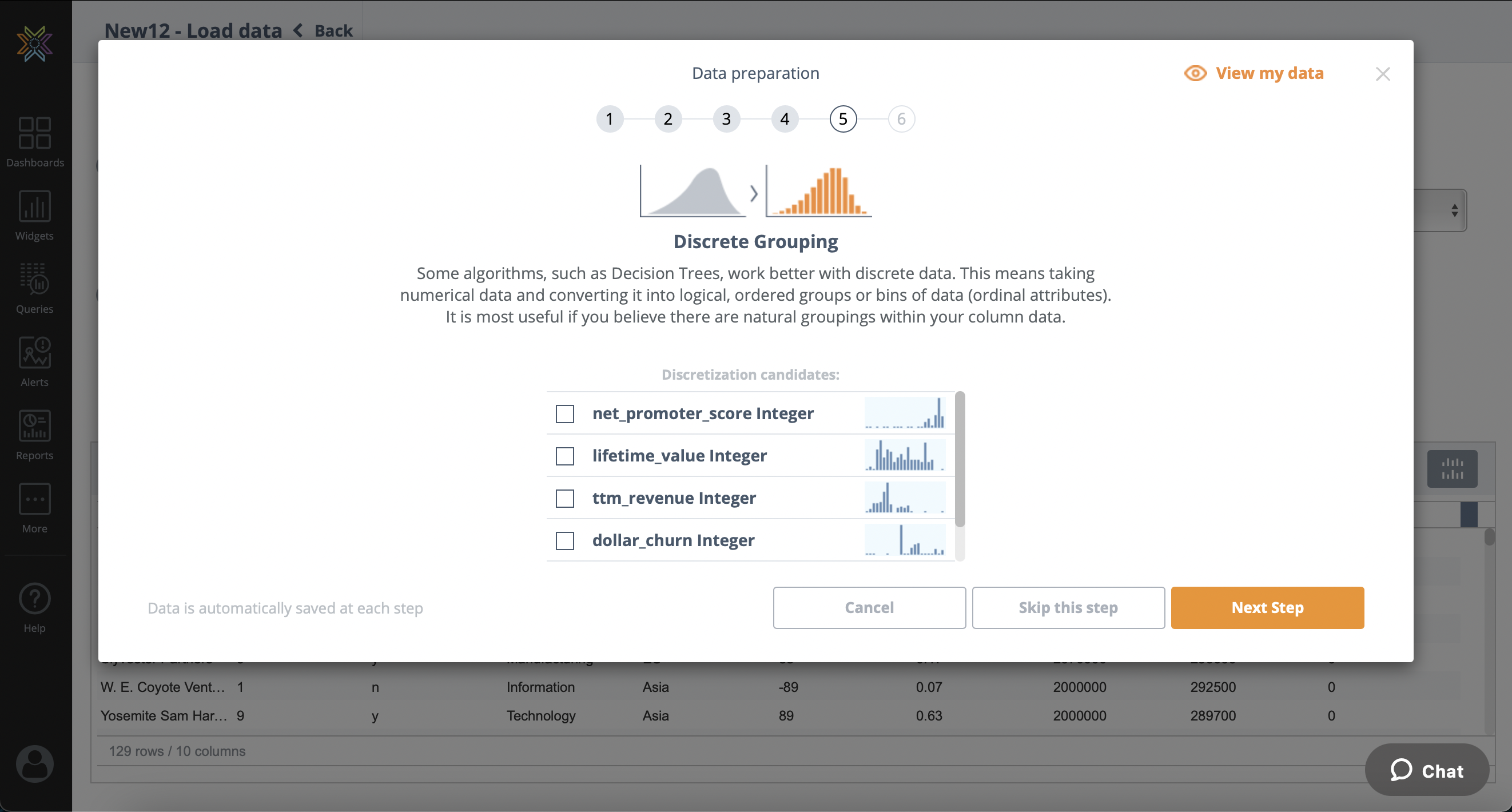
Discrete Grouping
Some algorithms, such as Decision Trees, work better with discrete data. This means taking
numerical data and converting it into logical, ordered groups or bins of data (ordinal attributes).
It is most useful if you believe their are natural groupings within your column data or if your numerical data has a large range of values (for example, -infinity → 7,000,000,000).
This step is optional and can be skipped.
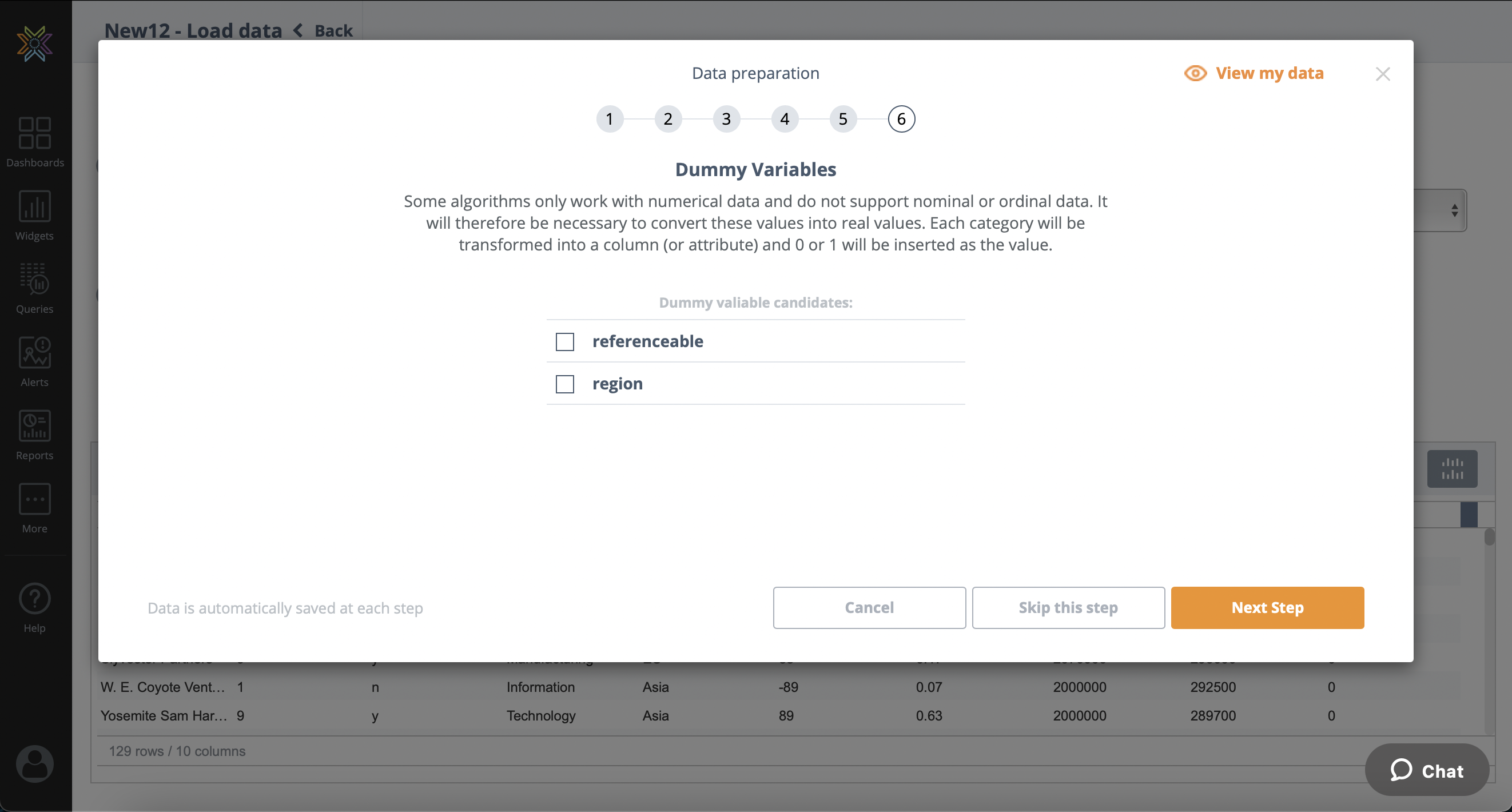
Dummy Variables
Some algorithms only work with numerical data and do not support nominal or ordinal data. It
will therefore be necessary to convert these values into real values. Each category will be
transformed into a column (or attribute) and 0 or 1 will be inserted as the value. This is called widening your dataset.
For example, a column called Gender typically has permissible string entries for ‘Male’, 'Female' and 'Not Specified'. If the value in a particular case is 'Male', then this would become three columns (one for each category), Gender:Male (with a value of 1), Gender:Female (with a value of 0), Gender:Not Specified (with a value of 0)
Existing column below would become three columns:
| existing column | value | new column | value |
| Gender | Male | Male | 1 |
| Female | 0 | ||
| Not Specified | 0 |
This step is optional and can be skipped.
This concludes the data preparation activity. Any decisions made along the way have been saved and a user can jump back to any previous step and make changes, if they wish.
The next step in our machine learning journey is to now select the model features that will help predict the outcome.